It has been quite a while since I took the GRE. During that time, I bought GRE核心词汇考法精析, GRE核心词汇助记与精练, and GRE词汇进阶与巩固 (新东方) on amazon, then wrote a script to extract the contents and made two sets of Anki cards.
Each set of cards includes audio (from Bing), phonetic symbols, and mnemonics (if available). The colors and styles of the cards can be customized directly by editing them in 卡片->样式.
The first set GRE核心词汇考法精析(再要你命3000)
This set combines GRE核心词汇助记与精练 and the mnemonic section from 不择手段背单词 found online.
The vocabulary inside includes all 3000 words, with complete audio.
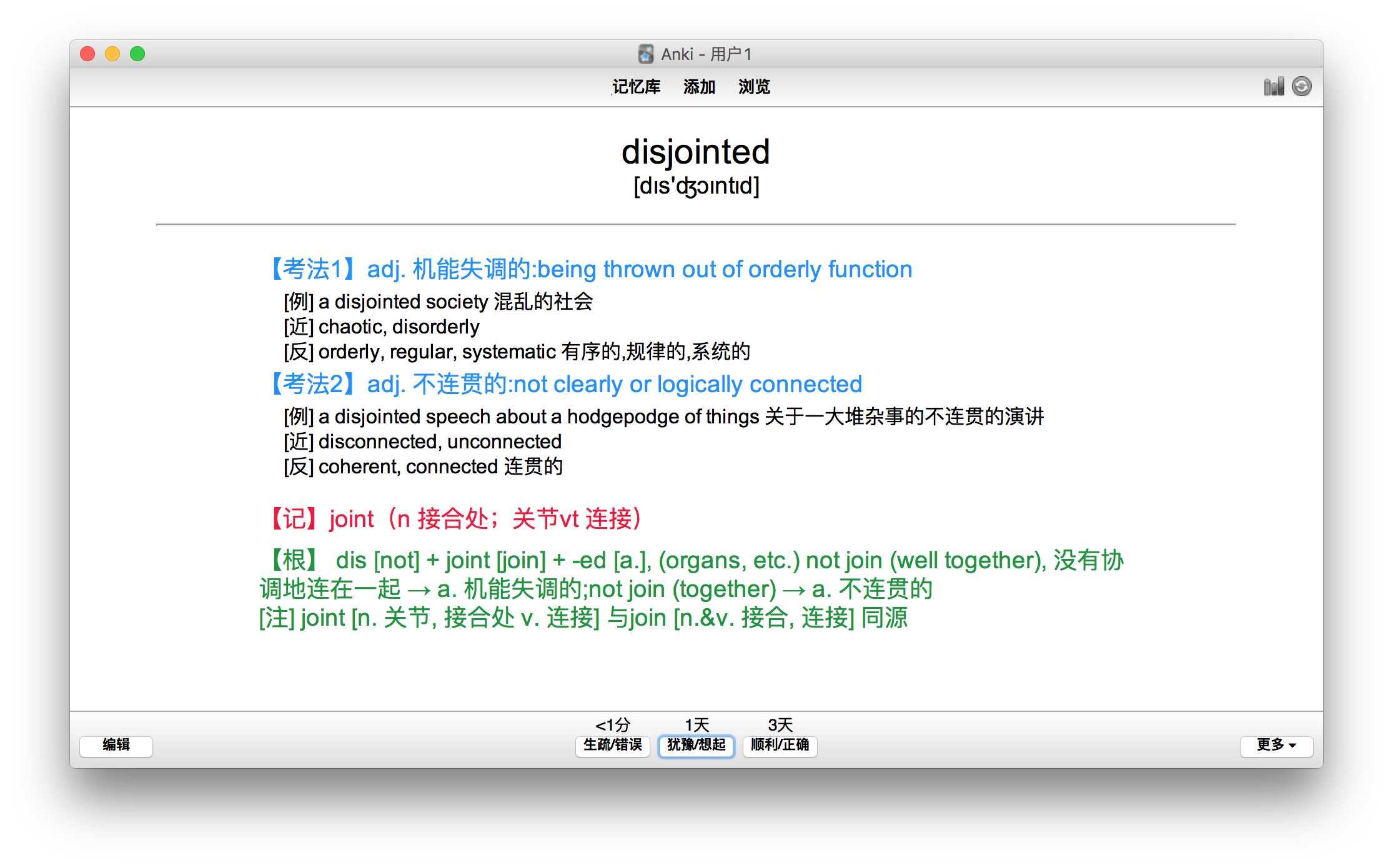
The first set
The second set GRE词汇进阶与巩固 (新东方)
This set combines GRE词汇进阶与巩固 (新东方) and a rather strange mnemonic system.
The vocabulary inside includes all the words from GRE词汇进阶与巩固 (新东方), a little over one thousand in total. I personally feel it is more reliable and suitable for people who do not have time to memorize all 3000 words.
The audio inside is incomplete, covering only the 3000-word portion, because I was too lazy to crawl it all over again at the time.
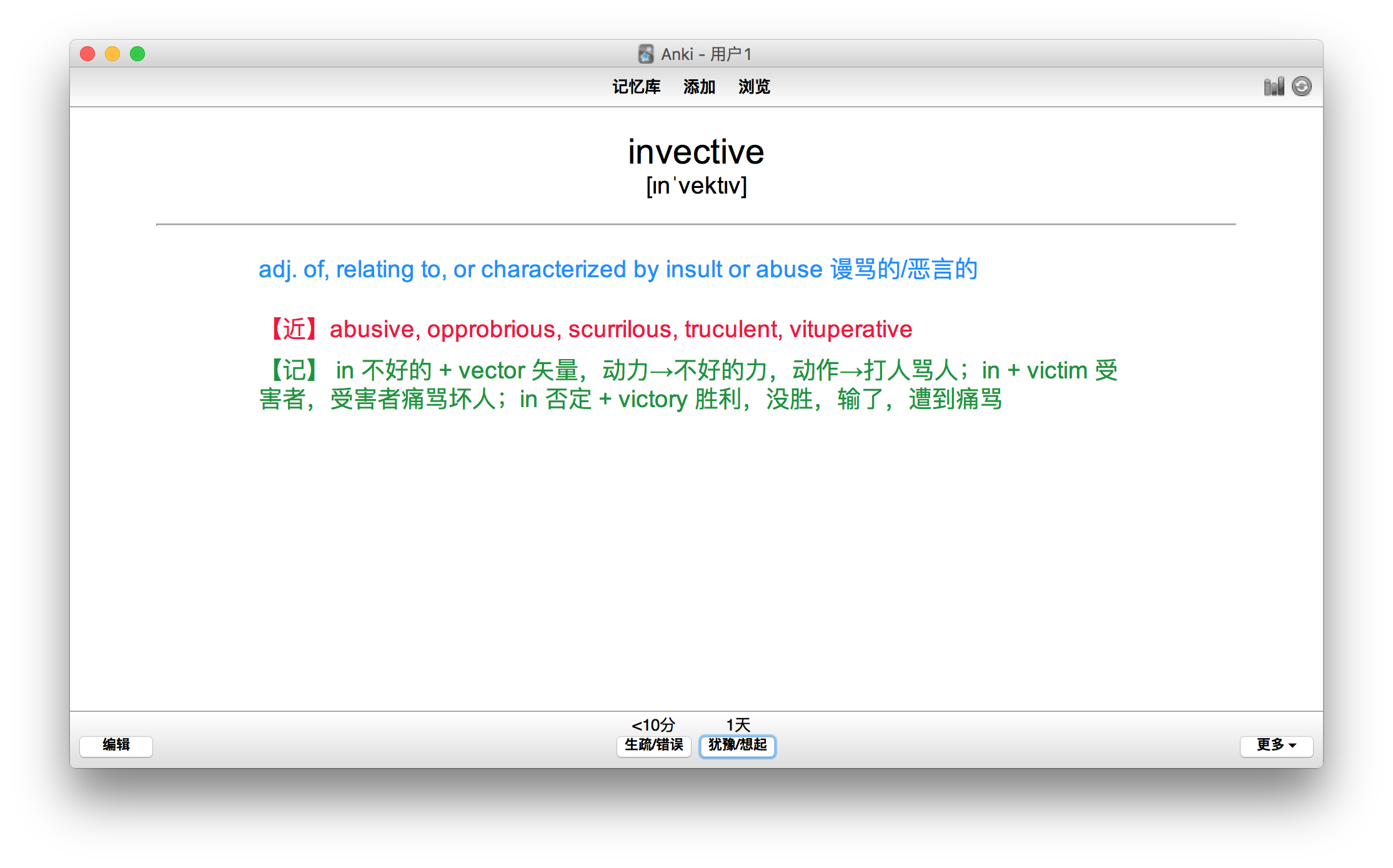
The second set
Finally, I wish all students taking the GRE can achieve good scores, and I hope I get a good ad as well...
By the way, here is a Python script for grabbing pronunciations from the Bing dictionary.``````
import urllib
import os
import string
import sys
import re
def getWord(word):
url = 'http://media.engkoo.com:8129/en-us/'+word+'.mp3'
# req = urllib2.Request(url)
# f = urllib2.urlopen(req)
print(word)
localDir = word+'.mp3'
try:
urllib.urlretrieve(url, localDir)
print("\t\t\tsuccess")
return True
except Exception as e:
print(e)
print("\t\t\terror")
return False
def parseVoc(filename):
file = open(filename, 'r')
count = 0
while True:
count = count + 1
line = file.readline().decode('utf-8')
line.strip()
line1 = line[0:len(line)-1]
if not line:
break
if len(line1) > 0:
# print("..."+line1)
print(''+str(count))
getWord(line1)
print("All success")
parseVoc('word.txt')